网络数据的基本单位是字节,Java NIO提供了ByteBuffer作为字节容器,但是这个类使用起来过于复杂和繁琐。Netty的替代方案是ByteBuf,既解决了JDK API 的局限性,又为开发者提供更好的API。
Netty的数据处理API通过2个组件暴露:ByteBuf 和 ByteBufHolder。下面是 ByteBuf API 的优点:
它可以被用户自定义的缓冲区类型扩展;
通过内置的复合缓冲区类型实现了透明的零拷贝;
容量可以按需增长;
在读和写2种模式之间的切换不需要调用ByteBuffer的flip()方法;
读和写使用了不同的索引;
支持方法的链式调用;
支持引用计数;
支持池化;
ByteBuf的工作原理
ByteBuf 维护了2个不同的索引:一个用于读、一个用于写。读取数据时,readerIndex 会向后移动对应的字节数;类似的,当写数据时,writerIndex 也会向后移动对应的字节数。
【ByteBuf的readerIndex和writerIndex示意图】
从上图可以看出,当readerIndex到达writerIndex时,如果此时再继续读取数据,将会报IndexOutOfBoundsException。调用ByteBuf时,调用 read / write 开头的方法将会推进对应的索引,而以set / get 开头的方法则不会。可以指定ByteBuf的最大容量,当写入超过这个阈值时,将会触发异常。
ByteBuf的使用模式
ByteBuf 是由2个索引分别控制读和写的字节数组。共有3中使用模式:堆缓冲区模式(Heap Buffer)、直接缓冲区模式(Direct Buffer)和复合缓冲区模式(Composite Buffer)。相对于JDK的ByteBuffer多了1种复合缓冲区模式。
堆缓冲区(Heap Buffer)
最常用的ByteBuf模式是将数据存储在JVM的堆空间中,又称为支撑数组(backing array)。就是将数据存放在JVM堆中,通过数组实现存储。
优点:由于数据存放在JVM堆中,可以实现快速的分配和释放,并提供了快速直接访问的方法。
缺点:执行IO操作时,存在数据在用户态和内核待之间的数据复制,增大了内存的使用。
ByteBuf heapBuf = Unpooled.buffer();
if (heapBuf.hasArray()) { // 检查ByteBuf 是否有一个 backing array
byte[] array = heapBuf.array(); // 如有,获取该数组的引用
int offset = heapBuf.arrayOffset() + heapBuf.readerIndex(); // 计算第一个字节的偏移量
int length = heapBuf.readableBytes(); // 获得可读字节数
handleArray(array, offset, length); // 使用数组、偏移量和长度作为参数调用你的方法
}
直接缓冲区(Direct Buffer)
Direct Buffer 数据堆外内存分配,不会占用堆容量。适用于Channel网络传输,避免了用户态到内核态的数据拷贝,实现Zero-Copy。
优点:用于Channel网络传输,可以实现零拷贝。
缺点:相对于JVM堆而言,直接内存的分配和释放相对复杂。
总体而言,对于涉及大量IO的场景,如网络读写。建议使用Direct Buffer,从而减少内存复制,提高性能。
ByteBuf directBuf = Unpooled.directBuffer();
if (!directBuf.hasArray()) { // 检查ByteBuf是否有数组支持, 如不是,则是直接缓冲区
int length = directBuf.readableBytes(); // 获取可读字节数
byte[] array = new byte[length]; // 分配一个新的数组用于保存字节数据
directBuf.getBytes(directBuf.readerIndex(), array); // 将字节复制到数组
handleArray(array, 0, length); // 调用业务方法
}复合缓冲区(Composite Buffer)
Composite Buffer 提供多个ByteBuf的聚合视图,可以按需添加/删除ByteBuf实例。这个是JDK的ByteBuff缺失的特性。
是一个聚合视图,提供一种访问方式,让使用者自有组合多个ByteBuf,避免了拷贝和分配新的缓冲区。
不支持访问其支撑数组。如果要访问,需要先将内容拷贝到堆内存再进行访问。
下图是将2个ByteBuf 组合在一起,没有进行数据复制动作,仅仅是创建了1个视图。
【CompositeByteBuf组合视图示意图】
CompositeByteBuf messageBuf = Unpooled.compositeBuffer();
ByteBuf headerBuf = Unpooled.buffer();
ByteBuf bodyBuf = Unpooled.directBuffer();
messageBuf.addComponents(headerBuf, bodyBuf); // 添加ByteBuf 到 CompositeByteBuf
messageBuf.removeComponents(0); // 删除组合的第一个 ByteBuf
for (ByteBuf buf : messageBuf) {
System.out.println(buf.toString());
}字节级操作
随机访问索引
ByteBuf的索引与Java数组的一样,从0到capacity() - 1。ByteBuf的API可以分为4大类:get*()、set*()、read*()、write*(),规则如下:
read*()和write*()将会推进对应的 readerIndex 和 writeIndex索引
get*()和set*()对readerIndex 和 writeIndex无影响
ByteBuf buffer = Unpooled.buffer();
for (int i = 0; i < buffer.capacity(); i++) {
byte b = buffer.getByte(i); // 不改变 readerIndex的值
System.out.println((char) b);
}顺序访问索引
ByteBuf 有读写索引,因此将存储区分为了3段,如下所示:
【ByteBuf的分段示意图】
可丢弃字节区
可丢字节区指的是 [0, readerIndex] 之间的区域。可调用discardReadBytes() 方法丢弃已经读过的字节,释放已经读取的空间。
discardReadBytes() 会将可读字节区向前覆盖,同时修改读写索引,整体看下来就是向数组头部平移。
【discardReadBytes() 平移过程示意图】
从上图可以看出,discardReadBytes() 虽然会增加可写区域的大小,但是会有数据复制的开销,如果频繁调用,对性能会有影响。
可读字节区
可读字节区是指 [readerIndex, writerIndex] 之间的区域,read*() 和 skip*() 开头的方法都会改变 readerIndex。
可写字节区
可写字节区是指 [writerIndex, capacity] 之间的区域,write*() 开头的方法都会改变 writerIndex。
索引管理
markReaderIndex() + resetReaderIndex() :markReaderIndex() 是先备份当前的 readerIndex,resetReaderIndex() 是将刚刚备份的 readerIndex恢复回来。常用于 dump ByteBuf 的内容,又不影响 readerIndex 的值。
readerIndex(int):设置 readerIndex 的值
writerIndex(int):设置 writerIndex 的值
clear():设置 readerIndex = writerIndex = 0,不会清除内容。因此 clear() 要比 discardReadBytes() 要轻量级的多,不会有数据拷贝,开销较小。
查找操作
查找 ByteBuf 指定的值,类似于String.indexOf("\|") 的操作。可以有下面 2 种方法:
使用 indexOf() 方法
使用ByteProcessor 作为参数查找指定值
ByteBuf buffer = Unpooled.buffer();
// 1. 使用indexOf()查找
buffer.indexOf(buffer.readerIndex(), buffer.writerIndex(), (byte)6);
// 2. 使用ByteProcessor 查找
int index = buffer.forEachByte(ByteProcessor.FIND_CR);其他操作
isReadable():如果有字节可读,则返回true
isWriteable():如果有空间可写,则返回true
readableBytes():返回可被读取的字节数
writeableBytes():返回可被写入的字节数
capacity():返回ByteBuf 可容纳的字节数,写满时会扩容,直到maxCapacity()
maxCapacity():返回ByteBuf 可容纳的最大字节数
hasArray():如果ByteBuf 是由字节数组支撑,返回true
array():如果ByteBuf 是由字节数组支撑,则返回数组;否则将抛出一个UnsupportedOperationException 异常
派生缓冲区
派生缓冲区是ByteBuf 的视图,可以由 duplicate()、slice()、slice(int, int)、Unpooled.unmodifiableBuffer(...)、Unpooled.wrappedBuffer(...)、order(ByteOrder)、readSlice(int) 方法创建的。这些方法返回一个新的ByteBuf,有自己的读写索引,但是存储区是共享的。这样创建的对象更加轻量级,减少了内存的复制。
派生出来的新ByteBuf 是一个视图,其有自己的读写索引,但数据区是共享的,看起来就像创建了一个新的 视图。
因为数据是共享的,因此当其中一个视图修改了数据,其他视图的数据也会被联动改变。
如果需要的是完全的数据副本,可以使用 copy() 或 copy(int, int) 方法。
在某些场景下,可以使用派生缓冲区的方式创建内存实例,这样可以减少内存复制。一个典型的例子:Kafka 消费者/备份副本 从主副本拉取数据时,从每个日志分段中获取的就是一个切片视图。其目的就是为了减少内存复制,直接将数据从网卡发送出去。
数据切片
Charset utf8 = Charset.forName("UTF-8");
ByteBuf buf = Unpooled.copiedBuffer("http://moguhu.com", utf8); // 创建一个包含特定字符串的 ByteBuf
ByteBuf sliced = buf.slice(0, 6); // 创建一个 [0, 6] 的内存视图,内容是:http://
System.out.println(sliced.toString(utf8)); // 打印出 http://
buf.setByte(0, (byte) 's'); // 更新索引 0 的字节
assert buf.getByte(0) == sliced.getByte(0); // 此处相同,因为数据区是共享的数据复制
Charset utf8 = Charset.forName("UTF-8");
ByteBuf buf = Unpooled.copiedBuffer("http://moguhu.com", utf8); // 创建一个指定字符串的ByteBuf
ByteBuf copy = buf.copy(0, 6); // 拷贝 http://
System.out.println(copy.toString(utf8)); // 打印结果 http://
buf.setByte(0, (byte) 's'); // 设置索引 0 的位置字符为 s
assert buf.getByte(0) != copy.getByte(0); // 因为数据为深拷贝,此处 h != s ByteBufferHolder 接口
通常情况下,除了实际的数据之外,我们还需要存储各种属性值。HTTP响应就是一个很好的例子,与数据一起的还有状态码、cookies等。为了处理这种常见的场景,Netty提供的ByteBufHolder 可以对这种常见的情况进行处理。ByteBufHolder 也对 Netty的高级功能进行了支撑,如缓存池化。下面是ByteBufHolder 用于访问底层数据和引用计数的方法。
content():返回 ByteBufHolder 所持有的所有 ByteBuf
copy():返回ByteBufHolder 的深拷贝
data():返回ByteBuf 保存的数据
ByteBuf 的分配
创建和管理 ByteBuf 有多种方式:按需分配(ByteBufAllocator)、Unpooled缓冲区和ByteBufUtil类。
按需分配(ByteBufAllocator)
Netty 通过ByteBufAllocator 实现了ByteBuf 的池化。Netty 提供池化和非池化的ByteBufAllocator,是否使用池化由应用程序决定。
ctx.channel().alloc().buffer():本质上是 ByteBufAllocator.DEFAULT
ByteBufAllocator.DEFAULT.buffer():返回一个基于堆或者直接内存存储的ByteBuf,默认是堆内存。
ByteBufAllocator.DEFAULT:有2种类型,UnpooledByteBufAllocator.DEFAULT(非池化)和PooledByteBufAllocator.DEFAULT(池化)。对于Java程序,默认使用池化,对于Android 使用非池化。
可以通过 Bootstrap 中的Config 为每个Channel提供独立的ByteBufAllocator实例。

上图的 buffer() 方法,返回一个基于堆或者直接内存存储的ByteBuf,默认是堆内存。
ByteBufAllocator.DEFAULT:可能是池化,也可能是非池化。默认是池化(PooledByteBufAllocator.DEFAULT)。
用户可以指定ByteBuf 的初始和最大容量。
ByteBufAllocator引用的获取,第一种可以从 channel 获得 ByteBufAllocator;第二种是从 ChannelHandlerContext获得。
Channel channel = ...;
ByteBufAllocator allocator = channel.alloc(); // 从 Channel 获得
ChannelHandlerContext ctx = ...;
ByteBufAllocator allocator2 = ctx.alloc(); // 从 ChannelHandlerContext 获得Unpooled缓冲区:非池化
Unpooled 提供静态方法辅助创建非池化的 ByteBuf,包含方法如下:
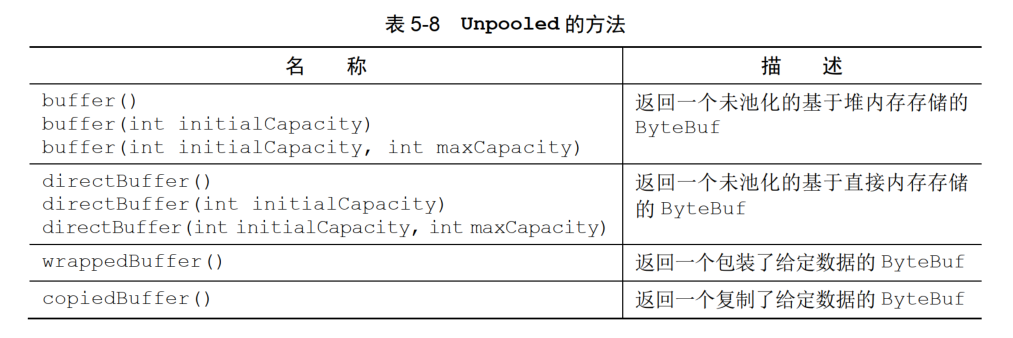
上面的buffer(),返回一个未池化的基于堆内存的ByteBuf
wrappedBuffer():创建一个视图,返回一个包装了给定数据的ByteBuf。
public void createByteBuf(ChannelHandlerContext ctx) {
// 通过Channel创建ByteBuf,实际上也是使用ByteBufAllocator, 因为ctx.channel().alloc()返回的就是一个ByteBufAllocator对象
ByteBuf buf1 = ctx.channel().alloc().buffer();
// 通过ByteBufAllocator.DEFAULT 创建
ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer();
// 通过 Unpooled 创建
ByteBuf buf3 = Unpooled.buffer();
}ByteBufUtil 类
ByteBufUtil 提供了用于操作 ByteBuf的静态的辅助方法:hexdump() 和 equals()
hexdump():以十六进制的形式打印ByteBuf的内容,在调试时可以这样打印,方便观察对比。
equals():判断2个ByteBuf 实例是否相等
引用计数
引用计数是一种对象所持有的资源不再被其他对象引用时,释放该对象所持有的资源来优化内存和性能的技术。Netty4为ByteBuf引入了引用计数,ByteBuf初始引用数为1,通过 release 可以 -1,为0时对象被回收。
ByteBuf byteBuf = Unpooled.copiedBuffer("moguhu.com").getBytes();
log.info("引用数 = {}", ReferenceCountUtil.refCnt(byteBuf));
ReferenceCountUtil.release(byteBuf); // 引用数为 -1如果试图访问已经被回收的对象,将会抛出IllegalReferenceCountException。
参考:《Netty实战》、《极客时间:Netty源码剖析与实战》



