ExtensionLoader 是 Dubbo SPI 的核心类,里面提供了一系列的静态方法用于获取扩展类的对象。下面我们看下 getExtension()、getAdaptiveExtension()和getActiveExtension() 的实现流程。
getExtension() 流程
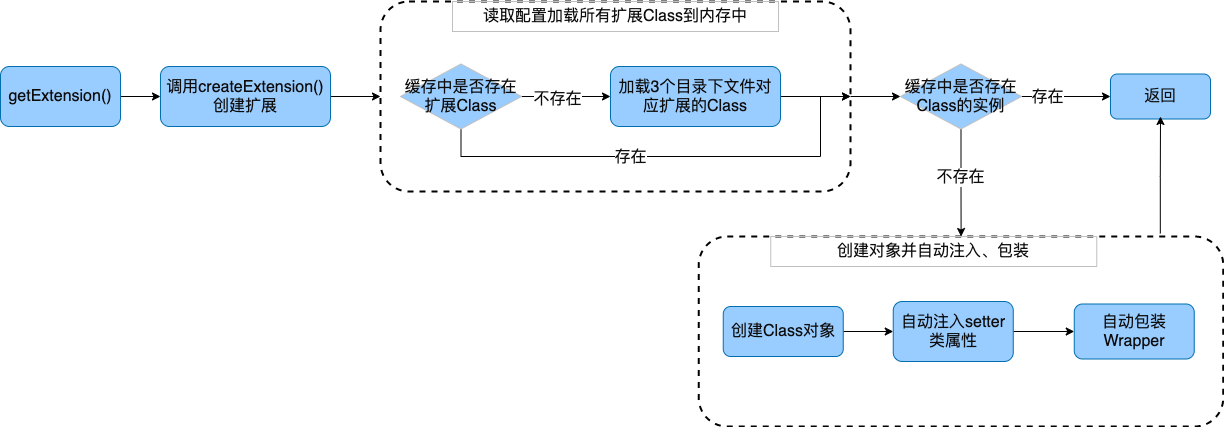
从上图可以看出,getExtension() 首先会调用 createExtension() 创建扩展,然后会读取该扩展的所有实现 Class 到内存中。当然这里面会判断之前是否已经加载过了 该接口的扩展Class。之后会判断这个实现类的Class 在内存中是否已经有了实例,如果之前已经new 过了对象,则直接返回即可。如果是第一次获取,则会实例化该Class,然后对该对象中的 setter 方法做自动自动注入扩展(通常是 Adaptive类型)。然后该扩展接口如果有 Wrapper 类,则会依次包装,也就是在new 出来的对象上再包上一层,最后返回这个 Wrapper 类的实例。当然对于 Wrapper 的实例也会对其 setter 方法进行自动注入相应的扩展。
getAdaptiveExtension() 流程
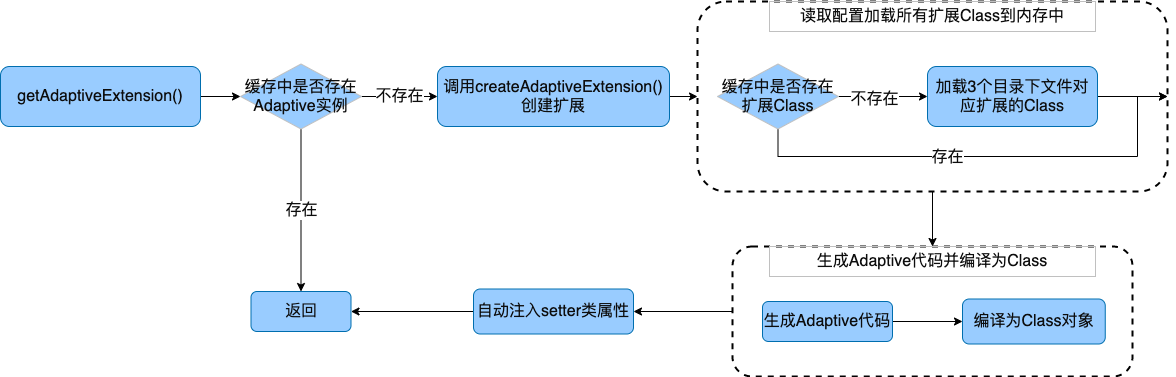
从上图可以看出,getAdaptiveExtension() 首先会判断缓存中是否已经初始化过Adaptive 对象,如果已经存在则直接返回。如果不存在,则调用 createAdaptiveExtension() 创建Adaptive扩展。此时和getExtension() 一样会去先加载接口的所有扩展Class到内存中,然后根据Adaptive注解生成Adaptive扩展类的代码,并编译为Class对象返回。之后会实例化该对象,并自动注入setter 属性,最后返回。
getActiveExtension() 流程

从上图可以看出,getActiveExtension() 首先会加载所有的扩展Class 到内存中,然后根据@Active 中配置的 before、after、order 进行排序。最后对于用户自定义扩展类,根据URL入参进行排序,最后返回符合条件的有序扩展类实例列表。
ExtensionFactory 实现
对于 ExtensionFactory,是Dubbo 后续版本引入的。笔者对比了 Dubbo 2.6.0 和 2.0.7 两个版本,发现这个工厂仅仅是在做 自动注入是被使用到的,而不是有些资料里面提到的 素有扩展的实例都是从该工厂中创建的。下面我们看下 2个版本的自动注入地方的代码实现。
2.0.7
private void injectExtension(Object instance) {
try {
for (Method method : instance.getClass().getMethods()) {
if (method.getName().startsWith("set") && method.getParameterTypes().length == 1 && Modifier.isPublic(method.getModifiers())) {
Class<?> pt = method.getParameterTypes()[0];
if (pt.isInterface()) {
try {
// 对于自动装配的 bean, 直接获取 adaptive 类型的扩展
Object adaptive = getExtensionLoader(pt).getAdaptiveExtension();
method.invoke(instance, adaptive);
} catch (Exception e) {
logger.error("fail to inject via method " + method.getName() + " of interface " + type.getName() + ": " + e.getMessage(), e);
}
}
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
}
2.6.0
private T injectExtension(T instance) {
try {
if (objectFactory != null) {
for (Method method : instance.getClass().getMethods()) {
if (method.getName().startsWith("set")
&& method.getParameterTypes().length == 1
&& Modifier.isPublic(method.getModifiers())) {
Class<?> pt = method.getParameterTypes()[0];
try {
// 如 setName, 解析后 property = name
String property = method.getName().length() > 3 ? method.getName().substring(3, 4).toLowerCase() + method.getName().substring(4) : "";
// 这里通过 ExtensionFactory 获取扩展类的实例
Object object = objectFactory.getExtension(pt, property);
if (object != null) {
method.invoke(instance, object);
}
} catch (Exception e) {
logger.error("fail to inject via method " + method.getName()
+ " of interface " + type.getName() + ": " + e.getMessage(), e);
}
}
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
return instance;
}通过上面的对比我们可以看出,ExtensionFactory 仅仅是在 setter 方法注入时,用于获取对应类型的扩展的工厂。对于Dubbo SPI 本身的扩展获取,和 ExtensionFactory 并没有什么直接关系,笔者认为其主要意义在于和 Spring Bean 的打通。下面我们介绍一下ExtensionFactory 的实现。
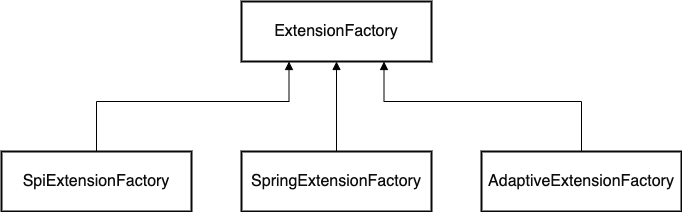
从 ExtensionFactory的实现可以看出,有3个实现类。其中 SpiExtensionFactory 里面实现是和 2.0.7 版本中的实现是一致的,也就是直接获取被注入类型的 Adaptive 扩展。SpringExtensionFactory 表示从 Spring 上下文中获取实例注入,其主要代码如下:
public <T> T getExtension(Class<T> type, String name) {
for (ApplicationContext context : contexts) {
if (context.containsBean(name)) {
Object bean = context.getBean(name);
if (type.isInstance(bean)) {
return (T) bean;
}
}
}
return null;
}上面的代码很简单,就是直接从 Spring 上下文中获取,但是 context 是怎么注入到其中的呢。对于Bean的组装,主要实在 dubbo-config 层进行组装的,这里面会监听Spring 的初始化,然后将context注入。最后一个是 AdaptiveExtensionFactory,当然也是通常使用的一个,主要原因在于其可以自动选择使用 SPI 还是Spring 的Bean,大概代码如下:
@Adaptive
public class AdaptiveExtensionFactory implements ExtensionFactory {
private final List<ExtensionFactory> factories;
public AdaptiveExtensionFactory() {
ExtensionLoader<ExtensionFactory> loader = ExtensionLoader.getExtensionLoader(ExtensionFactory.class);
List<ExtensionFactory> list = new ArrayList<ExtensionFactory>();
// 只有 SPI 和 Spring 2个
for (String name : loader.getSupportedExtensions()) {
list.add(loader.getExtension(name));
}
factories = Collections.unmodifiableList(list);
}
public <T> T getExtension(Class<T> type, String name) {
for (ExtensionFactory factory : factories) {
T extension = factory.getExtension(type, name);
if (extension != null) {
return extension;
}
}
return null;
}
}可以看出AdaptiveExtensionFactory 是@Adaptive 标注的,因此factories 中只有 2 个工厂,且用TreeSet 存储的顺序为 SPI、Spring。也就是说注入 Bean 会优先使用 Dubbo SPI 的扩展,然后再使用Spring 的Bean。
Compiler 动态编译
Compiler 类也是 Dubbo 后续版本中引入的,动态编译主要用于生成 Adaptive 类时使用的。在老的版本中,是直接在ExtensionLoader 中写死的用 javassist 进行编译的。在新的版本中,做了抽象并做了一定的改进。其类图大致如下:
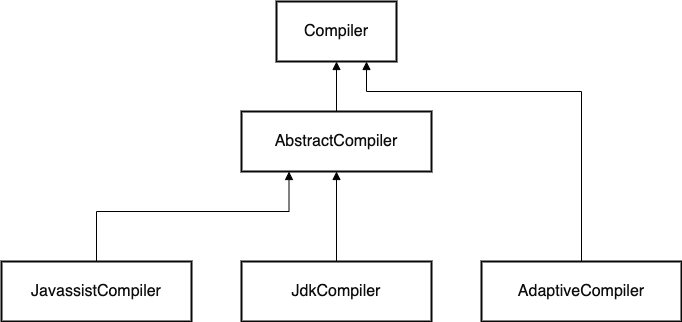
这里面和ExtensionFactory 的抽象比较类似,其中扩展主要有 Javassist 和 JDK 2种类型。这里面需要提一下的是,AbstractCompiler 这个类中的代码,首先他会拼接出全路径名,然后尝试Class.forName()加载这个类,这里是防止重复编译。如果已经加载过,此时就直接返回了。如果不存在,则调用子类方法去编译生成的code。
public Class<?> compile(String code, ClassLoader classLoader) {
code = code.trim();
Matcher matcher = PACKAGE_PATTERN.matcher(code);
String pkg;
if (matcher.find()) {
pkg = matcher.group(1);
} else {
pkg = "";
}
matcher = CLASS_PATTERN.matcher(code);
String cls;
if (matcher.find()) {
cls = matcher.group(1);
} else {
throw new IllegalArgumentException("No such class name in " + code);
}
// 生成类全路径名
String className = pkg != null && pkg.length() > 0 ? pkg + "." + cls : cls;
try {
// 尝试加载,失败则进行编译,防止重复编译
return Class.forName(className, true, ClassHelper.getCallerClassLoader(getClass()));
} catch (ClassNotFoundException e) {
if (!code.endsWith("}")) {
throw new IllegalStateException("The java code not endsWith \"}\", code: \n" + code + "\n");
}
try {
// 调用子类实现
return doCompile(className, code);
} catch (RuntimeException t) {
throw t;
} catch (Throwable t) {
throw new IllegalStateException("Failed to compile class, cause: " + t.getMessage() + ", class: " + className + ", code: \n" + code + "\n, stack: " + ClassUtils.toString(t));
}
}
}这里可以发现,原先的代码里并没有做防止重复编译的限制,而提取后则限制了。这是因为原先代码只在 ExtensionLoader 中使用,而其本身就会判断实例是否存在,也就是相当于防止了重复编译。这里面提取出来之后,可能会提供给更多的入口使用,因此做了限制。但是笔者看了下代码,也就ExtensionLoader 在生成 Adaptive 扩展时使用了。这从一定程度上看,这个抽象是不是有点鸡肋了。
参考:《深入理解Apache Dubbo 与实战》、Dubbo 2.6.0 源代码、Dubbo 2.0.7 源代码



