Kafka是一个分布式的、分区的、复制的提交日志服务。Kafka 使用提交日志作为最终的存储格式。
从之前的文章描述,我们可以了解到,在 Broker 端同一个 Topic 可以存储在不同的分区上面。每个分区可以有多个分区副本,其中多个副本中间有一个 Leader 副本。分区的多个副本中,只有 Leader 副本才可以给客户端提供读写服务。分区的每个副本都对应着一个 日志对象(Log),每个 Log 又包含多个 日志分段(LogSegment)。服务端将生产者的消息集存储到日志文件中,需要对消息集进行分段存储。如下图所示:
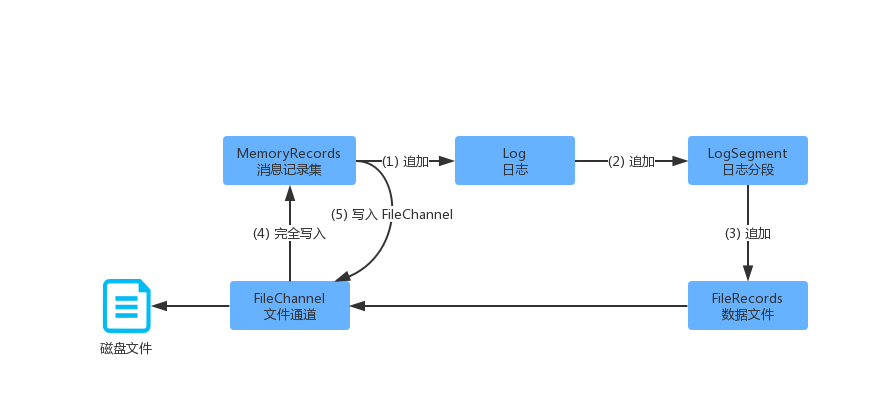
对上面的日志写入简要描述如下:
(1)每个分区对应的日志对象(Log),管理了分区的所有日志分段(LogSegment)。
(2)将消息集追加到当期那活动的日志分段,任何时刻,都只有 1 个活动的日志分段。
(3)每个日志分段对应一个数据文件和索引文件,消息内容会追加到数据文件中。
(4)消息集(MemoryRecords)最终会通过 FileChannel 写入到磁盘文件总。
消息结构
在生产者发送消息时,属于同一个分区的消息会以批次为单位进行发送。其中发送的消息结构,如下图所示:
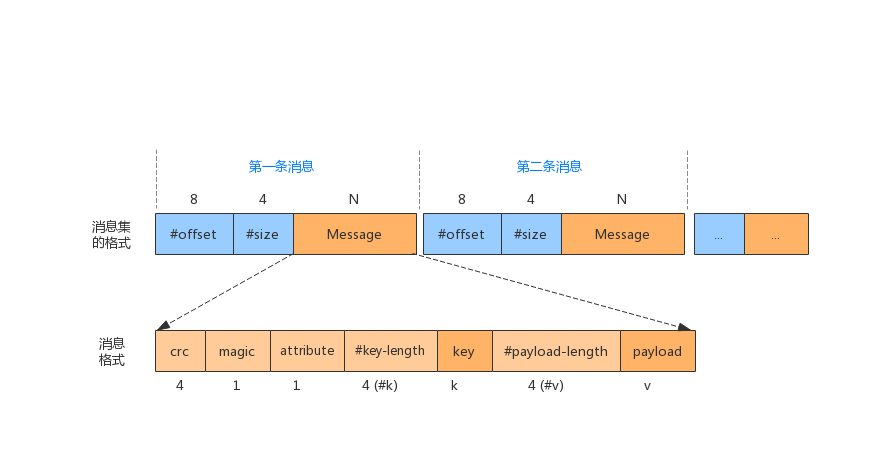
消息集合中每条消息由 3 部分组成:偏移量、数据大小、消息内容,如上图所示。
日志追加
服务端消息的追加,是以日志分段(LogSegment)为单位的。当日志分段累加到一定的阈值大小(1GB),都会创建一个新的 LogSegment,消息总是会追加到最新的日志分段当中去。每个日志分段都有一个 基准偏移量(baseOffset),这个偏移量是分区级别的绝对偏移量。有了这个基准偏移量,就可以算出每条消息的绝对偏移量。我们先看一个图,有一个感官的认知。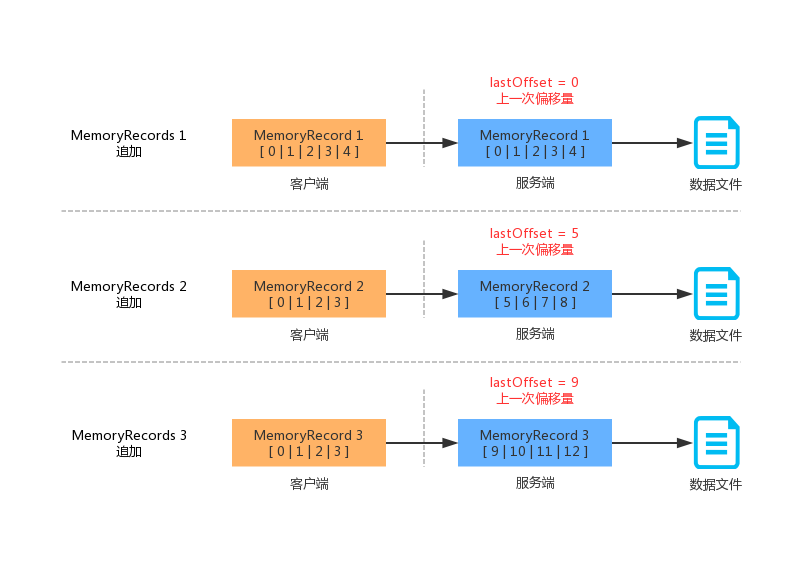
在实际的实现当中,会使用一个"下一个偏移量"(nextOffset)的值,去记录下一次要追加的位置,当然这个值最初也是根据 baseOffset(基准偏移量)计算得到的。下面我们看一下该值的计算过程:
(1)生产者发送消息给服务端,服务端会将这一批消息都追加到日志中。
(2)每条消息需要指定绝对偏移量,服务端会用 nextOffsetMetadata 的值作为起始偏移量。
(3)服务端将每条带有偏移量的消息写入到日志分段中。
(4)服务端会获取这一批消息中最后一条消息的偏移量,加上 1 后更新 nextOffsetMetadata。
(5)消费线程(消费者/分区副本)会根据这个变量的最新值拉取消息。
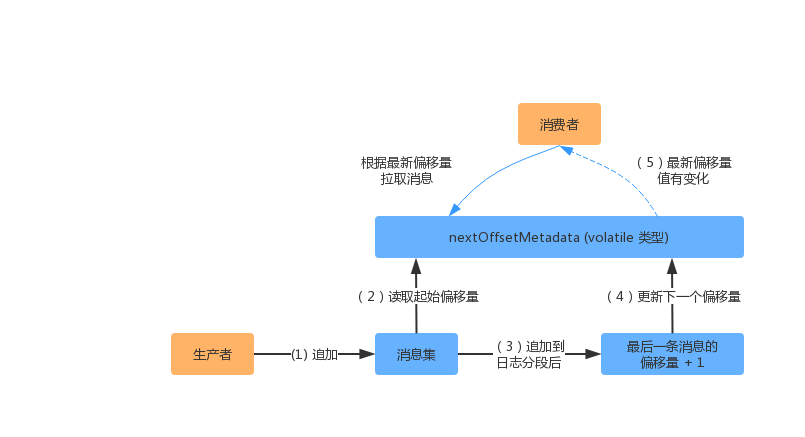
在服务端追加日志的时候,也会对这一批消息进行一些验证。其中包括了:消息太大或者消息无效会被直接丢弃,相对偏移量是否符合单调递增等。
参考:《Apache Kafka 源码剖析》、《Kafka技术内幕》、Kafka 源代码



