前面我们讲到了消费者端的网络模型,但是对于Kafka而言,在接收消息之前,消费者是必须要加入 group的。一个消费者 group 由一个或者多个消费者组成,原则上每个消费者都需要有一个 groupId。这个可以在KafkaConsumer创建的时候指定。当消费者组只有一个消费者时,此时可以认为就是点对点模式;当有多个消费者时,就可以认为是发布订阅模式。
对于Broker 端的TopicPartition 而言,一个Partition 只能被一个消费者消费。也就是说,假设一个Topic 有 3 个分区(TopicA),此时groupId 为test 的消费者组内有4 个消费者,此时组内的每个成员都订阅了TopicA。这个时候最多有3个消费者可以消费到数据,因为主题的分区只有3个。
Coordinator 组件
Coordinator 表示一类组件,其中包含了消费者端的 ConsumerCoordinator 和 Broker 端的 GroupCoordinator。在Broker 端,GroupCoordinator 负责的是:消费者 group 成员管理以及 offset 提交。消费者 offset 提交在老版本的 Kafka 中是存储在 Zookeeper 中的。新版本的 Kafka 中,将Topic 的消费 offset 存储在一个叫 __consumer_offsets 的主题中。这是一个 Kafka 内部主题,默认情况下会有 50 个分区,每个分区会有3个副本。
后面我们将会详细的讲解 ConsumerCoordinator 在客户端和 Broker 端的交互流程。其中主要包括,一个消费者如何加入 group 和 offset 提交。
ConsumerCoordinator 主体流程
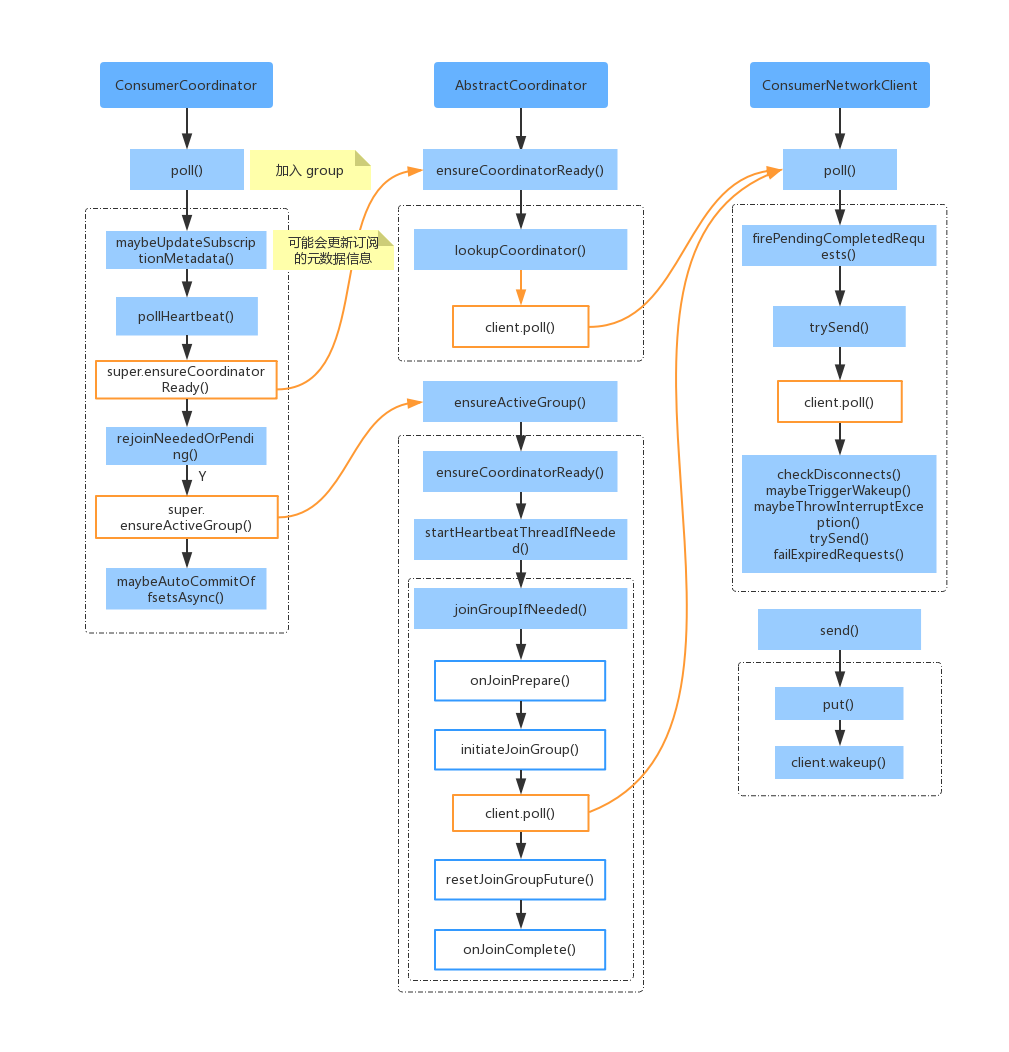
首先我们在调用 KafkaConsumer.poll() 时,首先会去调用 ConsumerCoordinator.poll() ,然后也会去调用位移提交的相关操作。对于 ConsumerCoordinator.poll(),也就是上图中的入口,下面看下入口 ConsumerCoordinator.poll() 的代码实现。
/**
* 消费者加入 Group,它确保了这个 group 的 coordinator 是已知的,并且这个consumer是已经加入group,也用于offset周期性的提交。
* 如果超时将会立即返回。
*/
public boolean poll(Timer timer) {
// 可能会更新订阅的元数据信息
maybeUpdateSubscriptionMetadata();
// 用于测试
invokeCompletedOffsetCommitCallbacks();
if (subscriptions.partitionsAutoAssigned()) {
/** 检查心跳线程运行是否正常, 如果心跳线程运行失败, 则抛出异常; 反之更新poll 调用的时间 */
pollHeartbeat(timer.currentTimeMs());
// coordinator 未知,初始化 Consumer Coordinator
if (coordinatorUnknown() && !ensureCoordinatorReady(timer)) {
return false;
}
// 判断是否需要重新加入group,如果订阅的 partition 变化或则分配的 partition 变化时,需要rejoin
if (rejoinNeededOrPending()) {
// 因为初始化的metadata刷新和初始化Rebalance存在竞态条件,在这里要确保metadata刷新在前面。这样可以保证在入组之前,订阅主题和Broker主题至少有一次匹配的过程。
if (subscriptions.hasPatternSubscription()) {
// 对于模式匹配订阅的Consumer,当一个Topic创建后,任何Consumer通过刷新metadata后发现新Topic后,都会触发一次Rebalance。因此此时可能会有大量的Rebalance操作,通过下面的backoff time判断会显著降低Rebalance的频率。
if (this.metadata.timeToAllowUpdate(timer.currentTimeMs()) == 0) {
this.metadata.requestUpdate();
}
if (!client.ensureFreshMetadata(timer)) {
return false;
}
maybeUpdateSubscriptionMetadata();
}
// 确保group是active;加入group;分配到订阅的partition
if (!ensureActiveGroup(timer)) {
return false;
}
}
} else {
// For manually assigned partitions, if there are no ready nodes, await metadata.
// If connections to all nodes fail, wakeups triggered while attempting to send fetch
// requests result in polls returning immediately, causing a tight loop of polls. Without
// the wakeup, poll() with no channels would block for the timeout, delaying re-connection.
// awaitMetadataUpdate() initiates new connections with configured backoff and avoids the busy loop.
// When group management is used, metadata wait is already performed for this scenario as
// coordinator is unknown, hence this check is not required.
if (metadata.updateRequested() && !client.hasReadyNodes(timer.currentTimeMs())) {
client.awaitMetadataUpdate(timer);
}
}
// 设置自动commit时,当定时达到时,执行自动commit
maybeAutoCommitOffsetsAsync(timer.currentTimeMs());
return true;
}
简单的描述一下上面的流程:
1、ensureCoordinatorReady() 的主要作用是发送GroupCoordinator请求,并建立连接。
2、判断是否需要加入group,如果订阅主题分区发生变化,或者新消费者入组等,需要重新入组。此时是通过ensureActiveGroup() 发送JoinGroup、SyncGroup,并获取到分配给自身的TopicPartition。
3、检测心跳线程是否正常,心跳线程需要定时向GroupCoordinator发送心跳,超过约定阈值就会认为Consumer离组,触发Rebalance。
4、如果设置的是自动提交位移,达到时间阈值就会提交offset。
后面将对于 ensureCoordinatorReady() 和 ensureActiveGroup() 详细说明一下。
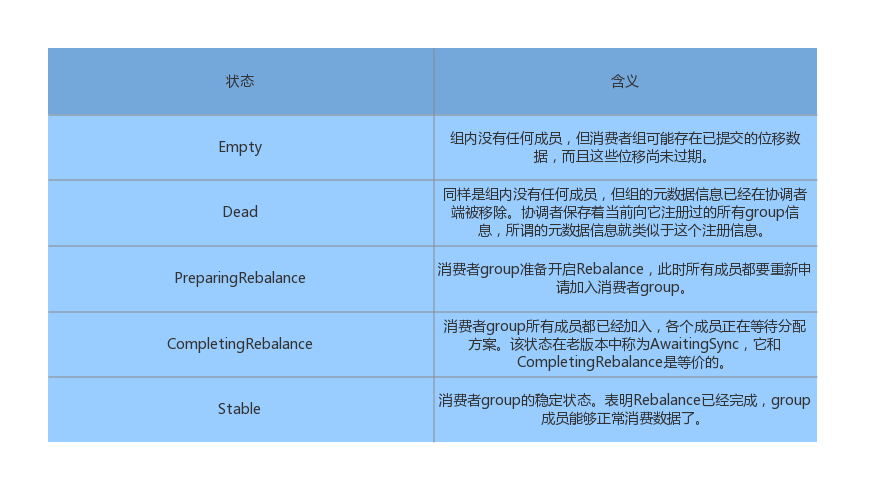
消费者group状态
对于消费者group的状态包含了下面几种
消费者group各个状态之间的流转如下所示
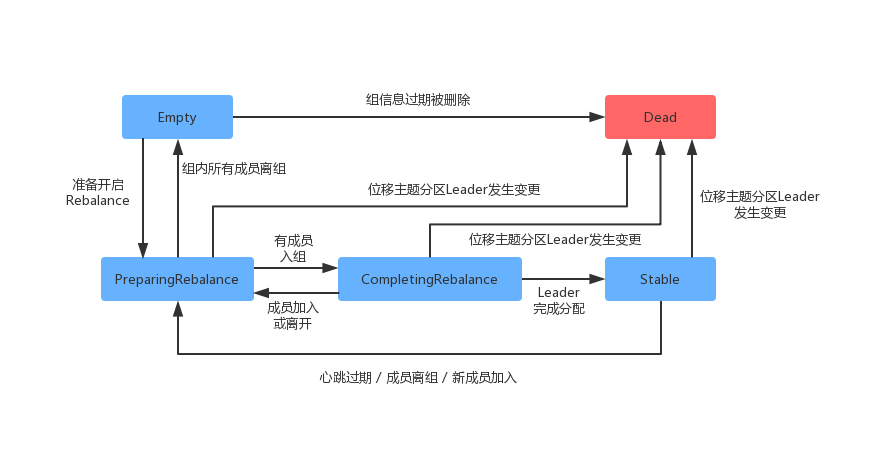
下面简单的描述一下状态流转过程:最开始消费者group是Empty 状态,当Rebalance 开启后,会被置于 RreparingRebalance 状态等待成员加入group。之后当有成员入组时,会变更到CompletingRebalance 状态等待分配方案。分配完成后会流转到Stable 状态完成充平衡。
当有新成员入组或者成员退出时,消费者group 状态从 Stable 直接变为 PreparingRebalance 状态,此时所有成员都需要重新加入group。当所有的成员都退出组时,状态会变为 Empty。Kafka 定期自动删除过期位移的条件就是,group要处于 Empty 状态。当消费者 group 停用了很长时间(超过7天),此时Kafka 就可能将其删除。
与Broker建立TCP连接
与Broker 建立TCP连接是通过 ensureCoordinatorReady() 方法实现的,下面我们看一下方法的具体实现。
/**
* 确保 coordinator ready 去接收请求 (已经连接,并可以发送请求)
*/
protected synchronized boolean ensureCoordinatorReady(final Timer timer) {
if (!coordinatorUnknown())
return true;
do {
// 获取 GroupCoordinator,并建立连接
final RequestFuture<Void> future = lookupCoordinator();
client.poll(future, timer);
if (!future.isDone()) {
// ran out of time
break;
}
// 如果获取的过程中失败了
if (future.failed()) {
if (future.isRetriable()) {
log.debug("Coordinator discovery failed, refreshing metadata");
client.awaitMetadataUpdate(timer);
} else
throw future.exception();
} else if (coordinator != null && client.isUnavailable(coordinator)) {
// 当找到了 coordinator,但是连接失败了,此时标记为 dead,然后重试
markCoordinatorUnknown();
timer.sleep(rebalanceConfig.retryBackoffMs);
}
} while (coordinatorUnknown() && timer.notExpired());
return !coordinatorUnknown();
}上面方法入口中,与Broker 端建立TCP 连接的主要逻辑委派给了 lookupCoordinator() 去实现。
/**
* 选择最空闲的节点, 发送 groupCoordinator请求
*/
protected synchronized RequestFuture<Void> lookupCoordinator() {
if (findCoordinatorFuture == null) {
// 选择一个连接数最少的节点(假装最空闲)
Node node = this.client.leastLoadedNode();
if (node == null) {
log.debug("No broker available to send FindCoordinator request");
return RequestFuture.noBrokersAvailable();
} else
// 发送请求并处理响应
findCoordinatorFuture = sendFindCoordinatorRequest(node);
}
return findCoordinatorFuture;
}然后发送GroupCoordinator 请求的详情如下:
/**
* 发送 CoordinatorRequest 请求
* 为 group 寻找 coordinator,发送 GroupMetadata 请求到Broker。
*/
private RequestFuture<Void> sendFindCoordinatorRequest(Node node) {
// 初始化 GroupMetadata 请求
log.debug("Sending FindCoordinator request to broker {}", node);
FindCoordinatorRequest.Builder requestBuilder = new FindCoordinatorRequest.Builder(new FindCoordinatorRequestData().setKeyType(CoordinatorType.GROUP.id()).setKey(this.rebalanceConfig.groupId));
// 请求发送之后的响应结果,委派给了 Handler 执行
return client.send(node, requestBuilder).compose(new FindCoordinatorResponseHandler());
}
// 对 GroupCoordinator 的 response 进行处理,回调
private class FindCoordinatorResponseHandler extends RequestFutureAdapter<ClientResponse, Void> {
@Override
public void onSuccess(ClientResponse resp, RequestFuture<Void> future) {
log.debug("Received FindCoordinator response {}", resp);
clearFindCoordinatorFuture();
FindCoordinatorResponse findCoordinatorResponse = (FindCoordinatorResponse) resp.responseBody();
Errors error = findCoordinatorResponse.error();
if (error == Errors.NONE) {
synchronized (AbstractCoordinator.this) {
int coordinatorConnectionId = Integer.MAX_VALUE - findCoordinatorResponse.data().nodeId();
/** 如果正确获取 GroupCoordinator 时, 建立连接,并更新心跳时间 */
AbstractCoordinator.this.coordinator = new Node(coordinatorConnectionId, findCoordinatorResponse.data().host(), findCoordinatorResponse.data().port());
log.info("Discovered group coordinator {}", coordinator);
// 初始化 tcp 连接
client.tryConnect(coordinator);
// 更新心跳时间
heartbeat.resetSessionTimeout();
}
future.complete(null);
} else if (error == Errors.GROUP_AUTHORIZATION_FAILED) {
future.raise(new GroupAuthorizationException(rebalanceConfig.groupId));
} else {
log.debug("Group coordinator lookup failed: {}", findCoordinatorResponse.data().errorMessage());
future.raise(error);
}
}
@Override
public void onFailure(RuntimeException e, RequestFuture<Void> future) {
clearFindCoordinatorFuture();
super.onFailure(e, future);
}
}接下篇:《Kafka消费者加入group流程(下)》



