在前面两篇文章中,我们讲述了Reactor网络模型的基本概念。那么Kafka客户端(包含生产者和消费者)的网络模型就是基于Reactor模式的。首先我们来看一下KafkaProducer网络模型中的几个比较核心的类之间的关系。
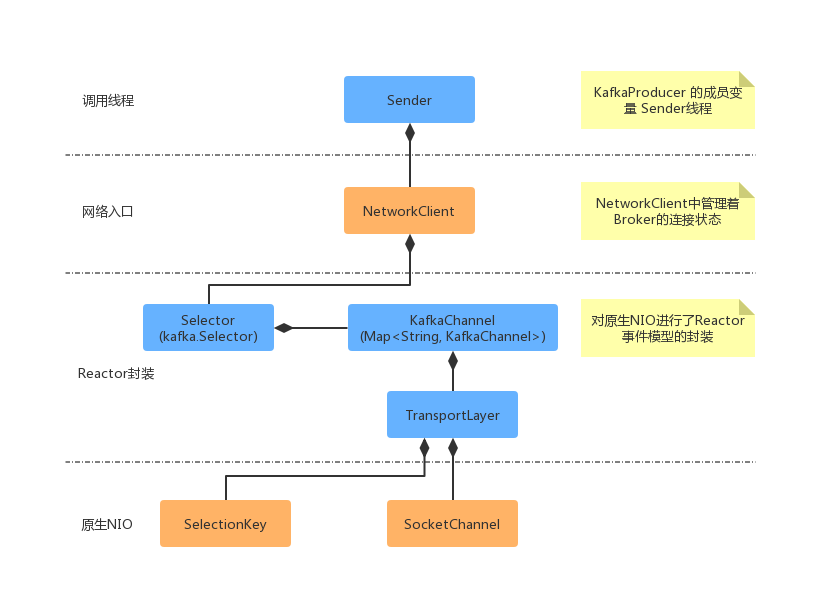
从上面的类关系图中可以看出,当KafkaProducer创建的时候,会创建一个Sender线程。Sender线程中组合了NetworkClient客户端,它管理着所有的连接状态,并且组合了Kafka自身实现的Selector。Kafka自身的Selector是对Java NIO的Reactor事件模型封装,Selector中组合了Map的数据类型,Map的key是nodeId(Broker的Id)。KafkaChannel中组合了TransportLayer(封装原生NIO),并且操作了具体的请求对象(Send)和响应对象(NetworkReceive)。
KafkaProducer网络主体流程
通过上面KafkaProducer核心类,我们看一下它们之间大体的调用关系,从而从全局了解网络模型。
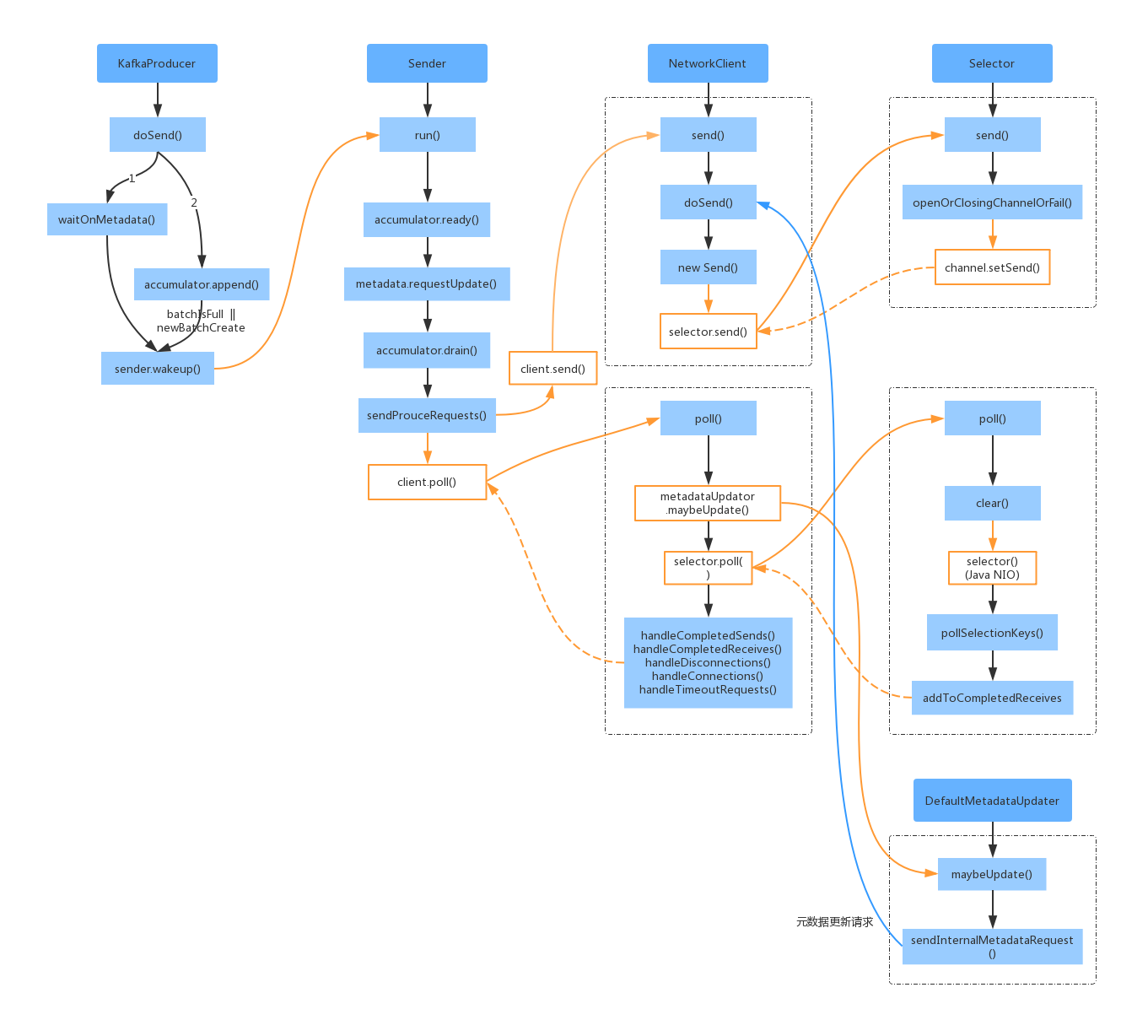
上面的总体流程图主要包含了两个方法 send() 和 poll(),其中 send() 方法是用来将请求暂存到内存中,实际的网络IO请求是通过 poll() 触发的。
KafkaProducer.doSend()
doSend() 是KafkaProducer发送消息的入口,其主要的方法如下:
1、waitOnMetadata():请求更新集群的元数据信息,并等待 topic 对应的 TopicPartition 分区可用。其中会调用 sender.wakeup();
2、accumulator.append():将消息写到对应的deque,如果对应的 deque 新建了一个 batch,则最后也会调用 sender.wakeup();
其中 sender.wakeup() 最终调用了Java NIO 中的 nioSelector.wakeup() ,表示如果 selector 阻塞的话,就唤醒。其中调用链为:Sender -> NetworkClient -> Selector(Kafka) -> Selector(Java NIO)
在doSend() 方法中调用wakeup() 方法的条件是 result.batchIsFull || result.newBatchCreated,意思就是 batch 已经满了,或者新的 batch 已经创建。
Sender 分析
通过前面的分析我们知道,主线程通过 KafkaProducer.send() 方法将消息放入 RecordAccumulator 中缓存,并没有实际的网络IO。而实际的网络IO 是在Sender 线程中异步执行的。
Sender 线程发送消息的大体流程如下:首先根据 RecordAccumulator 的缓存情况,筛选出可以向哪些 Node 节点发送消息(RecordAccumulator.ready());然后根据生产者各个Node的连接情况,过滤Node 节点;然后为每个 Node 节点生成一个请求;最后调用NetworkClient 将请求发出去。
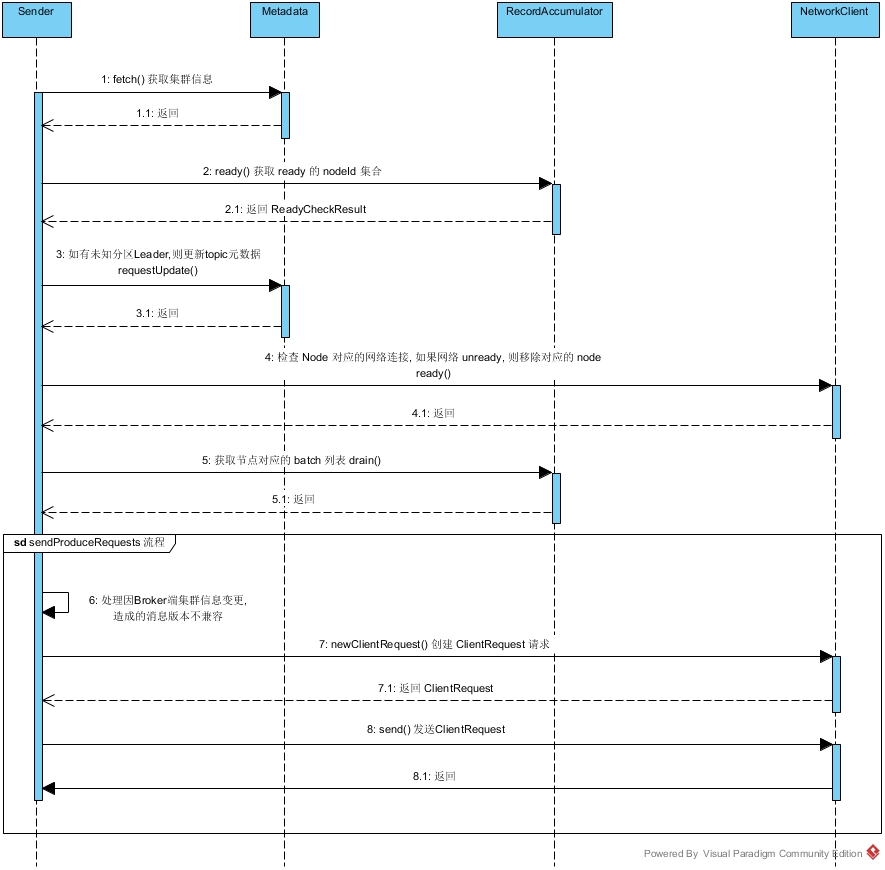
从上面泳道图中可以看出,Sender 线程的执行流程大致如下:
1、从 Metadata 获取 Kafka集群元数据信息;
2、调用 RecordAccumulator.ready() 方法,根据 RecordAccumulator 的缓存情况,选出可以向哪些 Node 节点发送消息,返回 ReadyCheckResult 对象;
3、ReadyCheckResult 对象中 unknowLeadersTopics 不为空,则调用 Metadata.requestUpdate() 方法,标记需要更新 Kafka 的集群信息;
4、针对 ReadyCheckResult 中 readyNodes 集合,循环调用 NetworkClient.ready() 方法,目的是检查网络IO 是否符合发送消息的条件。如果Node的网络不符合发送条件,则将其从 readyNodes 集合中移除;
5、对于 readyNodes 集合,调用 RecordAccumulator.drain() 方法,获得待发送消息集合;
6、处理超时消息(图中未展示);
7、然后进入 Sender.sendProduceRequests() 流程,将每个Node 的 batch 封装成 ClientRequest,然后调用 NetworkClient.send() 方法将请求写入 KafkaChannel 的 send 字段;
8、1-7 步骤封装在 Sender.sendProducerData() 方法中,最后调用 NetworkClient.poll() 执行真正的网络IO。同时还会处理服务端返回的响应,以及调用用户自定义回调等。
NetworkClient 分析
NetworkClient 中所有连接的状态由 ClusterConnectionStates 管理,底层使用 Map 实现,key 是 NodeId,value 是 NodeConnectionState 对象。
NetworkClient 是一个通用的网络客户端实现,生产者消费者都可以使用它。首先看下 NetworkClient.ready() 方法:
NetworkClient.ready()
/**
* 创建 node 的连接, 如果已经连接, 则返回 true; 否则创建一个连接
*/
public boolean ready(Node node, long now) {
if (node.isEmpty())
throw new IllegalArgumentException("Cannot connect to empty node " + node);
if (isReady(node, now))
return true;
if (connectionStates.canConnect(node.idString(), now))
// 如果没有对应 node 的连接, 则创建一个
initiateConnect(node, now);
return false;
}
NetworkClient.send()
NetworkClient.send() 方法主要是将请求设置到 KafkaChannel.send 字段中去,同时将请求添加到 InFlightRequests 队列中等待响应。
/**
* 将 Request 放入缓冲区, 等待发送。请求对应的节点 ready 才能被发送
*/
public void send(ClientRequest request, long now) {
doSend(request, false, now);
}
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now) {
String nodeId = clientRequest.destination();
if (!isInternalRequest) {
// 如果是 NetworkClient 外部发来的请求, 则校验对应的 node是否 ready。内部的则不用交验,内部的认为是已经校验过了
if (!canSendRequest(nodeId, now))
throw new IllegalStateException("Attempt to send a request to node " + nodeId + " which is not ready.");
}
doSend(clientRequest, isInternalRequest, now, builder.build(version));
}
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request) {
String destination = clientRequest.destination();
RequestHeader header = clientRequest.makeHeader(request.version());
// 构建 send 对象
Send send = request.toSend(destination, header);
InFlightRequest inFlightRequest = new InFlightRequest(clientRequest, header, isInternalRequest,
request, send, now);
/** 先加入队列, 还没开始发送 */
this.inFlightRequests.add(inFlightRequest);
// 暂存至 KafkaChannel 中的 Send 对象中
selector.send(send);
}NetWorkClient.poll()
我们知道 NetworkClient.send() 方法只是将请求存储到对应内存结构中,但是并没有进行网络发送。真正的网络IO 是由 NetworkClient.poll() 触发的,其主要实现的功能如下:
1、如果需要更新Metadata,则就发送Metadata请求;
2、调用 Selector.poll() 进行网络IO请求;
3、处理Server端的Response以及其他操作。
/**
* 执行网络请求
*/
@Override
public List<ClientResponse> poll(long timeout, long now) {
// 处理在发送过程中出现 UnsupportedVersionException 的 request
if (!abortedSends.isEmpty()) {
// 不需要进行本次 poll() 操作, 直接进行快速失败
List<ClientResponse> responses = new ArrayList<>();
handleAbortedSends(responses);
completeResponses(responses);
return responses;
}
/** 如有需要, 则更新Metadata */
long metadataTimeout = metadataUpdater.maybeUpdate(now);
try {
/** 执行网络I/O操作 */
this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
// 处理完成后的操作
long updatedNow = this.time.milliseconds();
List<ClientResponse> responses = new ArrayList<>();
/** 完成发送的处理器, 处理 completedSends 队列 */
handleCompletedSends(responses, updatedNow);
/** 完成接收的处理器, 处理 completedReceives 队列 */
handleCompletedReceives(responses, updatedNow);
/** 断开连接的处理器, 处理 disconnected 列表 */
handleDisconnections(responses, updatedNow);
/** 处理连接的处理器, 处理connected 列表 */
handleConnections();
handleInitiateApiVersionRequests(updatedNow);
/** 超时请求的处理器, 处理 InFlightRequests 中超时的请求 */
handleTimedOutRequests(responses, updatedNow);
// 执行所有 responses 中的回调
completeResponses(responses);
return responses;
}上面代码的主要执行流程如下:
1、metadataUpdater.maybeUpdate():如果 Metadata 需要更新,则就选择连接数最小的 node,发送 Metadata 请求。
2、selector.poll():调用 Kafka 自己实现的 Selector.poll() 进行网络请求,后面会分析 Selector。
3、handler*,这一连串的 handle 是网络请求执行完成之后的一系列操作;
3a、handleAbortedSends():处理在发送过程中出现 UnsupportedVersionException 的 request,本次poll() 会直接快速失败异常请求,不进行后续的 poll() 操作;
3b、handleCompletedSends():处理已经完成的 request,如果是那些不需要 response 的 request 的话,这里直接调用 request.completed(),request 的发送也就完成了;
3c、handleCompletedReceives():处理从 Server 端接收的 Receives,metadata 更新就是在这里处理的(以及 ApiVersionsResponse);
3d、handleDisconnections():处理连接失败那些连接,重新请求 metadata;
3e、handleConnections():处理新建立的那些连接(还不能发送请求,比如:还未认证);
3f、handleInitiateApiVersionRequests():对于新建立的连接,发送 apiVersionRequest(默认情况:第一次建立连接时,需要向 Broker 发送 ApiVersionRequest 请求);
3g、handleTimedOutRequests():处理 timeout 的连接,关闭该连接,并刷新 Metadata。
4、执行所有 responses 中的回调,completeResponses(responses)。
Selector (Kafka)分析
这里说的Selector 并不是 Java NIO 提供的 Selector,是Kafka 基于 Java NIO Selector的又一层封装。其中网络事件监听用的还是 Java NIO Selector。其中还有一个Map 存放了所有 Node 的网络套接字,下面介绍一下其主要的方法:
Selector.connect()
主要负责创建 KafkaChannel,并添加到 channels 集合中。
/**
* 创建Server端连接, 并关联到 nioSelector
* 注意:这里面初始化的连接是异步的,调用poll()的时候, 需要调用 connected() 去检查是否连接成功
*/
public void connect(String id, InetSocketAddress address, int sendBufferSize, int receiveBufferSize) throws IOException {
// 创建SocketChannel
SocketChannel socketChannel = SocketChannel.open();
SelectionKey key = null;
try {
// 配置 SocketChannel为非阻塞等
configureSocketChannel(socketChannel, sendBufferSize, receiveBufferSize);
/** 因为非阻塞模式, 可能在连接建立之前就已经返回, 后面会通过 finishConnect() 确认是否真正建立 */
boolean connected = doConnect(socketChannel, address);
// 在nioSelector 上面注册 OP_CONNECT 事件
key = registerChannel(id, socketChannel, SelectionKey.OP_CONNECT);
if (connected) {
// OP_CONNECT won't trigger for immediately connected channels
log.debug("Immediately connected to node {}", id);
immediatelyConnectedKeys.add(key);
key.interestOps(0);
}
} catch (IOException | RuntimeException e) {
if (key != null)
immediatelyConnectedKeys.remove(key);
channels.remove(id);
socketChannel.close();
throw e;
}
}
protected SelectionKey registerChannel(String id, SocketChannel socketChannel, int interestedOps) throws IOException {
SelectionKey key = socketChannel.register(nioSelector, interestedOps);
KafkaChannel channel = buildAndAttachKafkaChannel(socketChannel, id, key);
// 将 nodeId 和 kafkaChannel 绑定, 放到 channels 里面管理
this.channels.put(id, channel);
if (idleExpiryManager != null)
idleExpiryManager.update(channel.id(), time.nanoseconds());
return key;
}Selector.send()
Selector.send() 是由 NetworkClient.send() 调用的,其意图就是将请求缓存在 KafkaChannel 的 send 字段中,等待 poll() 时触发网络 IO。其代码大致如下:
/**
* 将 send 缓存到 KafkaChannel 的 send 字段中
*/
public void send(Send send) {
String connectionId = send.destination();
KafkaChannel channel = openOrClosingChannelOrFail(connectionId);
if (closingChannels.containsKey(connectionId)) {
// 如果连接关闭, 则加入到失败集合中
this.failedSends.add(connectionId);
} else {
try {
channel.setSend(send);
} catch (Exception e) {
channel.state(ChannelState.FAILED_SEND);
}
}
}Selector.poll()
在生产者客户端的代码中,poll() 是具体网络IO 执行的地方。当 KafkaChannel 可写时,发送 KafkaChannel.send 字段;当KafkaChannel可读时,读取 KafkaChannel.receive。读取到一个完整的 KafkaChannel.receive之后,会将其缓存在 stagedReceives 中。当一次 pollSelectionKeys() 完成后,会将 stagedReceives 中的数据转移到 completedReceives。最后调用 maybeCloseOldestConnection() 方法,关闭空闲连接。
/**
* Selector 轮询事件, 分别调用 KafkaChannel 的 read() 和 write()
*/
public void poll(long timeout) throws IOException {
boolean madeReadProgressLastCall = madeReadProgressLastPoll;
/** 清除上一次 poll 结果 */
clear();
boolean dataInBuffers = !keysWithBufferedRead.isEmpty();
if (hasStagedReceives() || !immediatelyConnectedKeys.isEmpty() || (madeReadProgressLastCall && dataInBuffers))
timeout = 0;
/* check ready keys */
long startSelect = time.nanoseconds();
/** 立即进行一次轮询, 或者阻塞(直到超时) */
int numReadyKeys = select(timeout);
long endSelect = time.nanoseconds();
this.sensors.selectTime.record(endSelect - startSelect, time.milliseconds());
if (numReadyKeys > 0 || !immediatelyConnectedKeys.isEmpty() || dataInBuffers) {
Set<SelectionKey> readyKeys = this.nioSelector.selectedKeys();
// Poll from channels that have buffered data (but nothing more from the underlying socket)
if (dataInBuffers) {
keysWithBufferedRead.removeAll(readyKeys); //so no channel gets polled twice
Set<SelectionKey> toPoll = keysWithBufferedRead;
keysWithBufferedRead = new HashSet<>(); //poll() calls will repopulate if needed
pollSelectionKeys(toPoll, false, endSelect);
}
/** 处理 I/O 事件的核心 */
pollSelectionKeys(readyKeys, false, endSelect);
// Clear all selected keys so that they are included in the ready count for the next select
readyKeys.clear();
pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);
immediatelyConnectedKeys.clear();
} else {
madeReadProgressLastPoll = true; //no work is also "progress"
}
}上面 poll() 的过程中,最核心的方法是 Selector.pollSelectionKeys(),它是处理IO 操作的核心方法,其中会分别处理 OP_CONNECT、OP_READ、OP_WRITE 事件,并会检测连接状态。
参考:《Apache Kafka 源码剖析》、http://matt33.com/2017/08/22/producer-nio/



